
En un coup d’œil
- En 2024, le Tribunal fédéral a examiné comment les échantillons devaient être établis, dans le contrôle de l’application des tarifs, afin d’obtenir une information fiable pour plus de 10 000 factures.
- La taille minimale de l’échantillon nécessaire pour un grand nombre de factures dépend de trois facteurs : la méthode d’échantillonnage, le niveau de confiance et la marge de sécurité.
- Un échantillon trop petit donne des résultats incertains, tandis qu’un échantillon trop grand entraîne des coûts plus élevés sans procurer aucun avantage.
Sur la base de quels critères faut-il constituer un échantillon pour obtenir un résultat fiable pour plus de 10 000 factures ? Le Tribunal fédéral a été confronté à cette question au printemps 2024, à l’occasion d’un arrêt portant sur le contrôle de l’application des tarifs dans l’assurance-maladie. Il devait examiner la plainte d’assureurs-maladie ayant découvert des incohérences dans la facturation de positions tarifaires d’imagerie par résonance magnétique (IRM).
Dans le cas d’espèce, un hôpital avait facturé la position tarifaire « IRM des os de la face, cavités sinusales » 35 fois plus souvent que deux ans auparavant. Une analyse détaillée avait permis d’établir que, sur plus de 10 000 factures, cet hôpital avait simultanément facturé presque le même nombre de fois la position « IRM du neurocrâne, vue d’ensemble ».
Forts de ce constat, les assureurs-maladie avaient fait examiner un échantillon de 40 factures anonymisées datant des années 2016 à 2018, pour lesquelles l’hôpital avait facturé les deux positions tarifaires d’IRM. Dans 36 de ces 40 cas, les soupçons d’application erronée du tarif ont été confirmés par l’autorité inférieure, à savoir le tribunal arbitral des assurances sociales du canton de Bâle-Ville.
Le Tribunal fédéral a exprimé des réserves de principe quant à la pertinence d’un échantillon de 40 factures seulement sur un total de plus de 10 000, mais n’a pas examiné plus en détail cette question du point de vue statistique. Dans cet article, je tente de combler cette lacune et d’apporter un certain nombre de précisions à la question suivante : comment un échantillon doit-il être constitué pour que les assureurs-maladie soient en mesure, avec une certitude statistique suffisante, de prouver (ou de rejeter) la thèse d’une application erronée des tarifs et de chiffrer le montant à récupérer ?
Un contrôle en deux étapes
Les assureurs-maladie procèdent normalement à un contrôle de l’application des tarifs en deux étapes. Dans un premier temps, ils analysent les positions tarifaires et les fournisseurs de prestations sélectionnés afin de rechercher d’éventuelles anomalies indiquant une mauvaise application des tarifs. Dans un second temps, les médecins-conseils des assureurs-maladie examinent un à un les cas retenus.
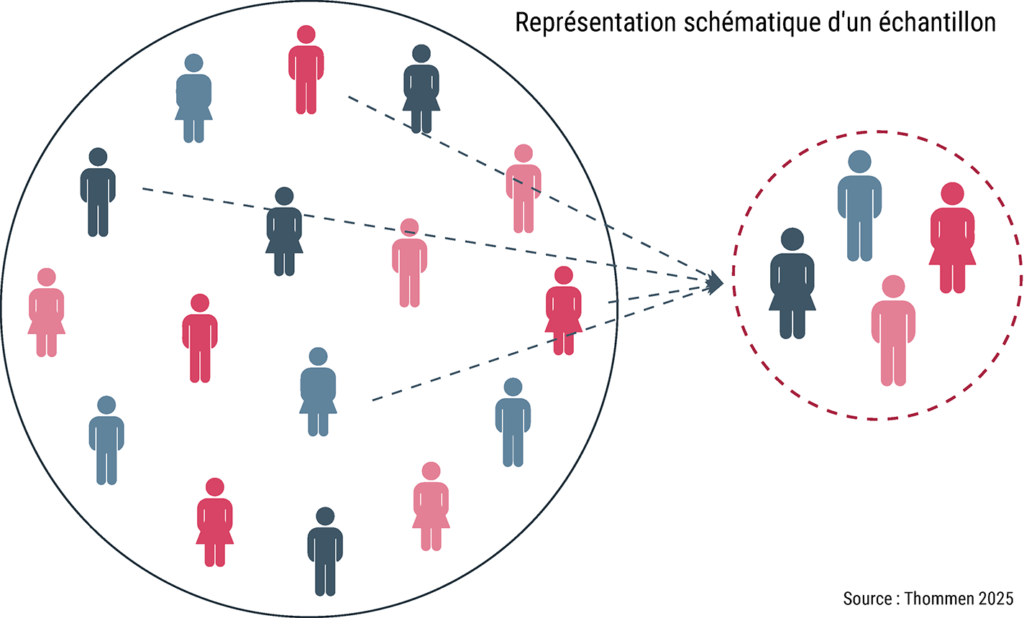
Comme leurs ressources limitées les empêchent d’examiner individuellement un nombre élevé de factures, les assureurs font appel à des méthodes statistiques qui permettent de tirer, sur la base d’un sous-ensemble limité de factures (appelé « échantillon »), des conclusions applicables à un vaste ensemble de factures (appelé « population » ou « univers statistique ») (voir l’illustration).
Choix de la meilleure méthode
Du point de vue statistique, la première exigence est de choisir la méthode d’échantillonnage de manière à obtenir des résultats fiables pour l’ensemble de l’univers statistique. On parle alors souvent d’échantillon représentatif.
La méthode la plus importante est l’échantillonnage aléatoire simple, qui consiste à choisir des factures au hasard : chacune a ainsi la même probabilité d’être intégrée dans l’échantillon. De nombreuses méthodes d’échantillonnage s’écartent toutefois de ce principe, par exemple parce que la taille de l’univers statistique est inconnue ou que le choix d’un échantillon aléatoire simple serait beaucoup plus coûteux qu’une autre méthode. Dans l’exemple qui nous occupe, il n’y a aucune raison de s’écarter de l’échantillonnage aléatoire simple : l’univers d’environ 10 000 factures est connu et accessible, et toutes les factures peuvent être examinées à peu près au même coût.
Une autre méthode souvent utilisée est celle de l’échantillonnage stratifié. Elle consiste à diviser la population en groupes homogènes sur la base d’une caractéristique ciblée. L’échantillonnage est ensuite appliqué de façon aléatoire aux membres de chacune des strates en respectant leurs parts respectives par rapport à l’univers statistique. Si les différences concernant la caractéristique ciblée sont importantes entre les strates, mais faibles à l’intérieur même de chacune d’elles, cette méthode offre l’avantage de réduire l’incertitude d’échantillonnage. La taille minimale de l’échantillon permettant d’obtenir des informations sur l’univers concerné est ainsi automatiquement réduite.
Dans notre exemple d’une possible application erronée de deux positions tarifaires pour une IRM, nous ne disposons toutefois d’aucune information sur les différences entre ou au sein des strates potentielles. De plus, on peut supposer que la réalisation d’une IRM est standardisée en raison de la séquence préprogrammée de l’imagerie sur l’appareil, et que les factures sont, dans l’ensemble, très similaires (ou homogènes) entre elles. La méthode d’échantillonnage stratifié aurait donc peu de chances d’aboutir pour démontrer de manière statistiquement indiscutable devant un tribunal l’existence d’une application erronée des tarifs.
Taille de l’échantillon
Pour être en mesure de porter un jugement fiable sur un univers statistique, il faut accorder de l’importance non seulement à la méthode d’échantillonnage, mais aussi à la taille de l’échantillon. Un échantillon trop petit ne fournit pas d’information fiable sur l’ensemble des factures lors du contrôle de certaines d’entre elles. À l’inverse, un échantillon trop grand entraînerait des coûts élevés, sans pour autant améliorer de manière significative la fiabilité de l’estimation.
Une fois la méthode d’échantillonnage déterminée, la taille minimale de l’échantillon nécessaire pour obtenir une information fiable sur la population peut être induite sur la base de deux paramètres.
Le premier est le niveau de confiance, qui indique le degré de certitude que l’on peut avoir dans l’exactitude d’une estimation. Plus le niveau de confiance est élevé, plus le degré de certitude l’est également. La convention qui s’est imposée tant dans la recherche que dans la pratique consiste à fixer le niveau de confiance recherché à 95 %.
Le deuxième paramètre est la marge dite de sécurité. Même en cas d’application systématiquement erronée des tarifs, il peut arriver que certaines positions tarifaires aient été correctement facturées. Pour en tenir compte, les assureurs-maladie ne partent souvent pas du principe que 100 % des factures sont erronées. Ils supposent plutôt, par exemple, que le tarif a été correctement appliqué dans moins de 20 % des factures. Dans cet exemple, la marge de sécurité est donc de 20 %. Les prétentions financières de l’assureur en matière de restitution sont, dans ce cas, réduites de 20 % par rapport à la valeur totale des positions tarifaires vraisemblablement surfacturées.
Il n’existe pas, du point de vue statistique, de valeur correcte, ou communément admise comme marge de sécurité. L’Office of Inspector General du ministère américain de la Santé, qui contrôle les factures du programme Medicare (programme public d’assurance-maladie aux États-Unis), recommande une marge de sécurité de 25 % au plus (Ekin 2019).
En supposant un niveau de confiance de 95 %, la marge de sécurité retenue permet de déterminer la taille minimale de l’échantillon nécessaire pour contrôler l’application d’un écart tarifaire sur 10 000 factures similaires. Si cette marge est fixée à 10 %, un échantillon aléatoire simple de 97 factures sera nécessaire ; un échantillon de 25 factures sera suffisant avec une marge de sécurité de 20 %, ou même de 17 factures avec une marge de 25 %.
La maîtrise des méthodes statistiques permet de tirer des conclusions probantes sur un très grand nombre de factures à partir d’un échantillon de petite taille. Si l’on se réfère à l’arrêt du Tribunal fédéral mentionné, cela signifie qu’un échantillon de 40 factures sera suffisant pour tirer une conclusion pour l’ensemble de l’univers statistique. Une condition est toutefois de recourir à un échantillonnage aléatoire simple, où chaque facture doit avoir la même probabilité d’être intégrée à l’échantillon.
Bibliographie
Ekin, Tahir (2019). Statistics and health care fraud: How to save billions. Boca Raton, Chapman Hall/CRC Press.
